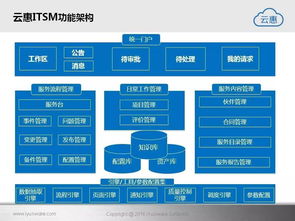
在當今快節奏的商業環境中,高效、精準的考勤管理已成為企業運營中不可或缺的一環。它不僅關系到員工的薪酬核算,更影響著團隊的協作效率與企業的合規性。金柚子考勤軟件服務,正是順應這一需求而生,致力于通過智能化、數字化的手段,為企業提供一套全面、靈活且可靠的考勤管理解決方案。
核心功能:全方位覆蓋考勤管理場景
金柚子考勤軟件的核心在于其功能的全面性與深度定制能力。它通常具備以下關鍵模塊:
- 多樣化考勤方式:支持多種打卡方式以適應不同工作場景,包括但不限于:
- 移動端GPS/藍牙打卡:方便外勤、遠程或靈活辦公的員工,確保打卡位置真實有效。
- 人臉識別/指紋打卡:適用于固定辦公場所,確保身份唯一性,杜絕代打卡現象。
- Wi-Fi打卡:員工連接指定企業網絡即可完成打卡,簡便快捷。
- 網頁端打卡:為長期居家辦公或使用特定設備的員工提供便利。
- 智能排班與規則引擎:企業可根據部門、崗位的不同,靈活設置復雜多樣的班次(如標準工時、綜合工時、彈性工時、輪班制)。系統能夠自動匹配班次,并內置強大的規則引擎,自動計算遲到、早退、缺勤、加班時長,并與國家勞動法規動態同步,確保計算結果的準確性與合規性。
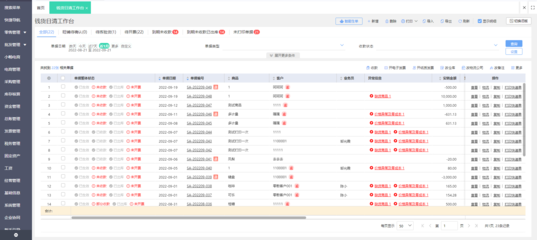
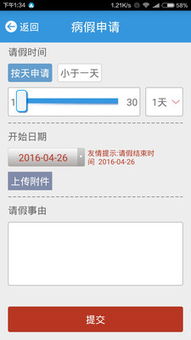
- 請假、出差與加班流程一體化:將考勤與OA流程深度整合。員工可直接在APP或網頁端發起請假、出差、加班等申請,審批流程電子化、可視化。審批通過后,數據自動同步至考勤統計,無需人工二次錄入,極大提升效率并減少差錯。
- 實時數據報表與可視化分析:管理者可通過儀表盤實時查看團隊出勤狀況、異常率、加班趨勢等關鍵數據。系統提供多維度、可定制的統計報表,幫助企業從宏觀層面分析人力投入與產出,為管理決策提供數據支持。
- 無縫集成與開放接口:優秀的考勤系統不應是信息孤島。金柚子考勤軟件通常提供標準API接口,能夠與企業現有的人力資源管理系統(HRMS)、財務薪資系統、OA辦公系統等無縫對接,實現數據流的自動貫通,避免信息割裂。
服務價值:超越工具的管理賦能
金柚子考勤軟件服務的價值,遠不止于一個記錄上下班時間的工具。它為企業帶來的深層益處包括:
- 提升運營效率與透明度:自動化處理替代了大量手工核對與計算工作,將HR和管理者從繁瑣的事務性工作中解放出來。所有流程在線、記錄可追溯,營造公平、透明的管理氛圍。
- 保障用工合規,控制風險:通過內置的合規規則和提醒機制,幫助企業規避因考勤、加班計算不當引發的勞動糾紛和法律風險,保護企業與員工雙方的合法權益。
- 優化勞動力成本:精準的工時數據有助于企業分析人力配置效率,識別不必要的加班成本,從而更科學地進行人力資源規劃和預算控制。
- 增強員工體驗與滿意度:便捷的移動端操作、清晰的個人考勤日歷、快速的流程審批,提升了員工的使用體驗。彈性考勤選項也能更好地適配現代職場對工作靈活性的需求。
- 支持管理決策:基于考勤大數據分析,管理層可以洞察組織效能、團隊狀態,為優化工作流程、調整排班策略、改善員工福利提供事實依據。
選擇與實施:成功落地的關鍵考量
企業在選擇類似金柚子這樣的考勤軟件服務時,應重點關注以下幾點:
- 靈活性與可配置性:能否滿足企業獨特且可能變化的考勤規則需求。
- 系統的穩定與安全性:數據是否安全加密,服務是否高可用,保障核心人事數據的萬無一失。
- 供應商的服務能力:是否提供專業的實施培訓、及時的技術支持和持續的版本更新。
- 成本效益:綜合考量軟件許可費、實施費、維護費與所能帶來的效率提升和風險降低價值。
###
總而言之,金柚子考勤軟件服務代表了現代企業考勤管理向數字化、智能化轉型的先進方向。它通過技術手段將復雜的考勤事務規范化、流程化、數據化,不僅解決了企業日常管理的痛點,更成為驅動組織效率提升、促進合規經營、賦能人才管理的重要基礎設施。對于尋求降本增效、提升核心競爭力的企業而言,投資一套成熟可靠的智能考勤系統,無疑是一項具有長遠價值的戰略選擇。